Card Pickup
pick_up_left, pick_up_right
Policy Bench
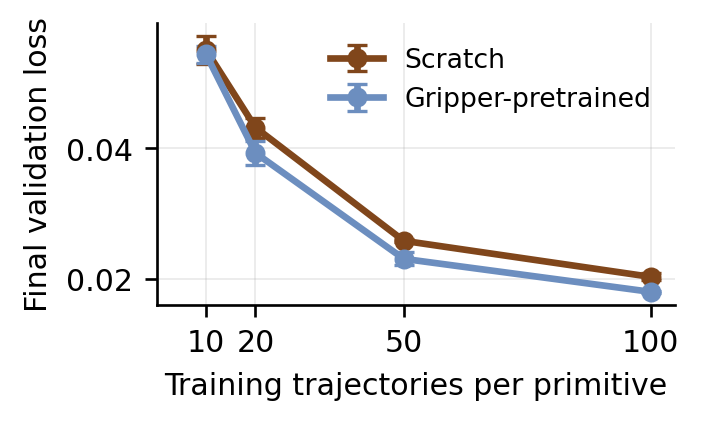
The policy bench isolates low-level dexterous execution from poker strategy. Every policy—pretrained VLAs and from-scratch baselines alike—is trained and evaluated under the same observation, action, rollout, and scoring interface on the physical ShadowHand–UR10e setup. A four-level rubric separates nominal task completion from scene-preserving execution, because a primitive can locally succeed while displacing cards or chips enough to block later actions.
Primitives
Directional labels are in the robot-facing tabletop frame: push moves chips away from the robot into the forward betting region; pull moves them back.
pick_up_left, pick_up_right
put_down_left, put_down_right, show_left, show_right
push_5, push_10, push_50, push_100
pull_5, pull_10, pull_50, pull_100
Scoring Rubric
Primitive completed and the tabletop remains usable for subsequent actions.
Goal achieved, but execution disturbs the scene enough to prevent normal continuation.
Primitive not completed, but the scene remains stable enough for retry.
Primitive fails and the environment must be reset before continuing.
SPSR = SP / N (only clean successes). TCR = (SP + DC) / N (any completion).
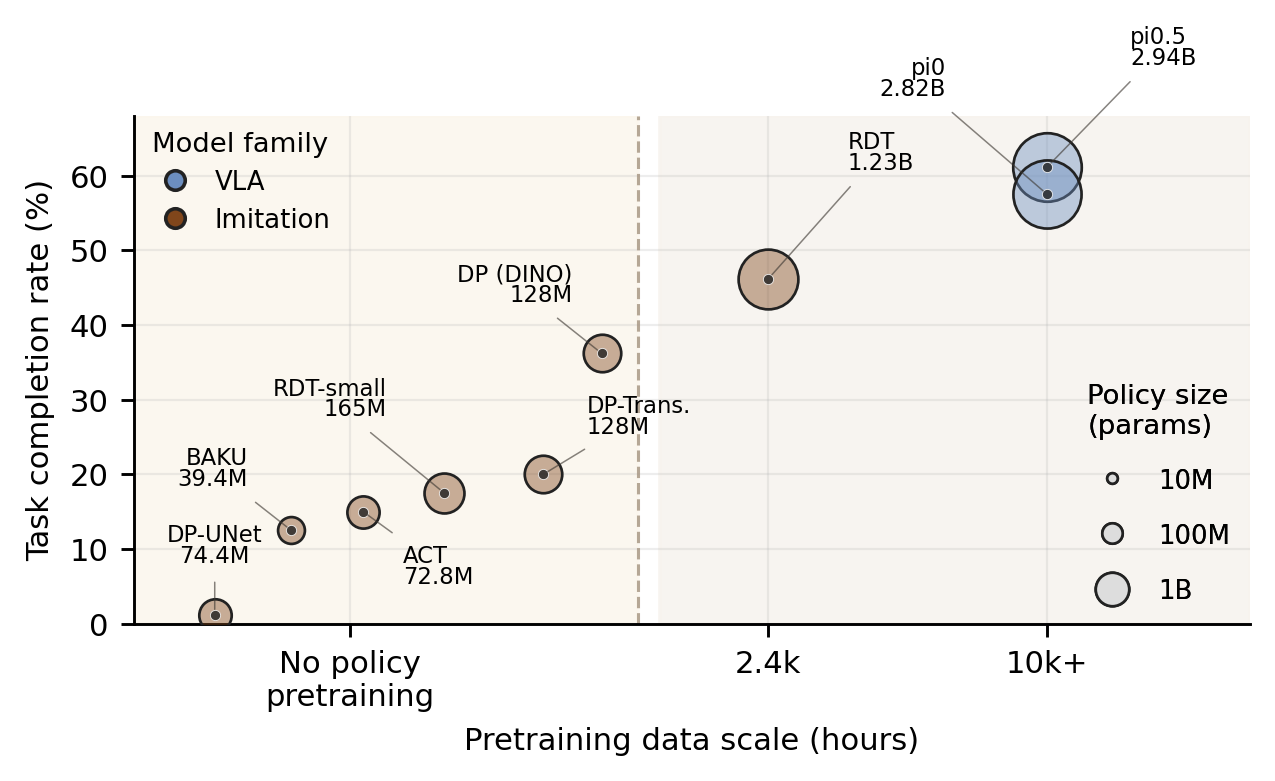
Results
| Policy | Family | Params | SP | DC | TF | DF | SPSR | TCR |
|---|---|---|---|---|---|---|---|---|
| π0.5 | Pretrained | 2.94B | 38 | 11 | 31 | 0 | 47.5% | 61.2% |
| π0 | Pretrained | 2.82B | 38 | 8 | 33 | 1 | 47.5% | 57.5% |
| RDT | Pretrained | 1.23B | 24 | 13 | 40 | 3 | 30.0% | 46.2% |
| DP (DINO) | From-scratch | 128M | 21 | 8 | 48 | 3 | 26.2% | 36.2% |
| DP-Transformer | From-scratch | 128M | 11 | 5 | 46 | 18 | 13.8% | 20.0% |
| RDT-small | From-scratch | 165M | 11 | 3 | 59 | 7 | 13.8% | 17.5% |
| ACT | From-scratch | 72.8M | 8 | 4 | 67 | 1 | 10.0% | 15.0% |
| BAKU | From-scratch | 39.4M | 5 | 5 | 67 | 3 | 6.2% | 12.5% |
| DP-UNet | From-scratch | 74.4M | 1 | 0 | 79 | 0 | 1.2% | 1.2% |
Interface
At each rollout step the policy receives top-down, third-person, and wrist-mounted RealSense RGB-D observations, the current 30-D arm+hand joint state, and a task condition (natural-language text for pretrained models, discrete instruction ID for from-scratch baselines). It returns a short-horizon sequence of joint-position targets.
105 teleoperated demonstrations per primitive, with a fixed 100-train / 5-validation split.
Joint-position targets for the 6-DOF UR10e arm and 24-DOF Shadow Dexterous Hand.
GPU inference runs behind a ZeroMQ endpoint; the robot client sends observations and executes returned chunks.
Physical evaluation uses 80 primitive-level trials per policy, grouped into pickup, push, pull, and put-down/show.
Policies
| Policy | Family | Conditioning | Implementation |
|---|---|---|---|
| π0.5 | Pretrained | Language | OpenPI bridge maps three camera streams and robot state; absolute joint-action targets. |
| π0 | Pretrained | Language | Same OpenPI bridge as π0.5; default delta joint motion before conversion. |
| RDT | Pretrained | T5 tokens | 1B-class diffusion Transformer adapted from gripper to 30-D joint space with SigLIP patches. |
| RDT-small | From-scratch | T5 tokens | Reduced-capacity RDT variant, randomly initialized and trained from scratch. |
| DP (DINO) | From-scratch | Instr. ID | Diffusion policy with frozen DINOv2 features and Transformer denoiser. |
| DP-Transformer | From-scratch | Instr. ID | Diffusion policy Transformer trained from scratch. |
| DP-UNet | From-scratch | Instr. ID | Lightweight diffusion policy with trainable ResNet encoders and 1D UNet denoiser. |
| ACT | From-scratch | Instr. ID | CVAE Transformer decoding deterministic action chunks at inference. |
| BAKU | From-scratch | Instr. ID | Deterministic action-token Transformer adapted to the 30-D command space. |
Figures